Did Sweden cheat at Eurovision?
By Guillaume Filion, filed under
Twitter,
Eurovision,
information retrieval.
•
•
In my previous post, I promised to go deeper into IMDB reviews, but I defer it until I deal with a more pressing issue.
Last Saturday was the Eurovision song contest. Somehow, my girlfriend managed to convinced me to sit through it (apologies to my fellow disincarnated academic researchers for such a treachery to our quest for knowledge).
Outside the epic performance of Ireland, already consecrated in the pantheon of memes, the show was plain boring. More specifically, it was redundant. Many songs were duplicates of each other and most were clear wannabes of successful artists (poor Amy, if you had seen what Italy did to you).
It was such a surprise, a shock I should say, that Sweden won the contest with the song Euphoria. Not that it was bad. Rather, that it was exactly like the songs we keep hearing every summer for more than 20 years. So, is this me getting old and not being able to recognize what's good music, or is there something fishy going on? I realized that the voting process is completely opaque and that nothing says that the IT counts the votes in a fair way. It would be so easy for the organizers to rig the contest and sell the first place to whichever country offers most. Just one line of code in the script that counts the votes and you're done! Nobody would ever notice it!!
This is where I decided to investigate. On an original idea of my girlfriend, I set out to download all the tweets of that day (May 26, 2012) with the mention "eurovision". Assuming that the Twitter community is an unbiased sample of the voters, we predicted that Sweden should actually be mentioned very often. At least more often than the other countries. I put the code I used to download the tweets in the following technical section.
git clone git@github.com:sixohsix/twitter
# Install it if need be.
git clone git@github.com:ptwobrussell/Mining-the-Social-Web
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | |
The hostility started at 00:00:07 UTC with ...
Eurovision Song Contest 2012: Final börjar på SVT1 klockan 21:00 #SVT1 http://t.co/dfGynpGQ
... and ended at 23:59:59 UTC with
RT @Queen_UK: Is that what they actually look like in Finland? #eurovision
In-between 2,886,410 tweets were posted. How do we go about analyzing them? In principle that's very simple: count all the tweets that speak about Sweden and compare it to the counts of other countries. But there is a 'but'. When it became clear that Sweden had won, there was probably massive tweeting about it, which inflates the count tremendously. So we need to see how much people were twitting about Sweden before the results.
Let us start by seeing the timing of twitting activity on Saturday May 26. Already we realize that the problem is more complicated than it looks. The first tweet of the day shown above (in Swedish) reminds us that Babel is a reality in Europe and that we have to deal with multiple languages. If the English were not thrilled by the performance of Sweden, chances are that there will be few tweets containing "Sweden". So we need to make sure that we cover the main languages of Europe. I chose English, German, Spanish and French as my working languages... sorry for the others.
grep -i 'swed\|su[^d]de\|suecia\|schweden'
I plotted the results in the figure below, which says it all. I showed the total number of tweets, which peaked at 25,000 per minute around 19.30 UTC and went down to almost nothing by the end of the day. We can clearly see massive twitting about a country at the time of its performance. I show here Russia, Sweden and Moldova, Russia because it came second, and Moldavia because it was the last show, telling us when people starting to vote, or to tweet about their vote.
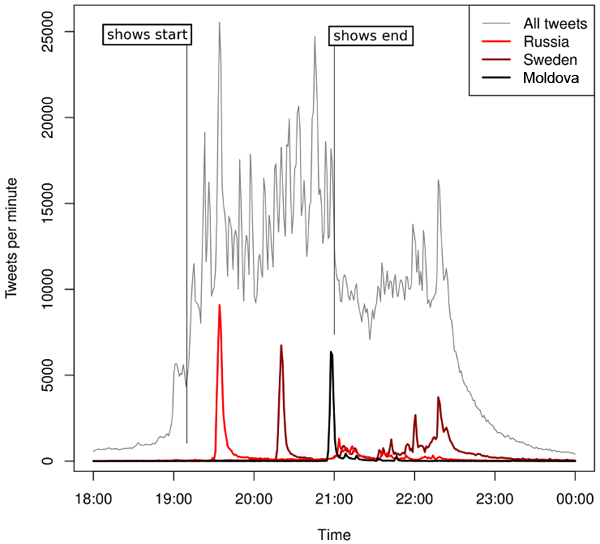
As you can see, there was more twitting about Russia during their performance, and the twitting about Moldova, which scored a mediocre 11-th rank out of 26, is substantially similar to that of Sweden. But if we look at the twitting activity between 21:00 and 21:30 UTC, we see that Russia and Sweden were higher than Moldova (and other countries as I could check). So this is the time when people expressed thei opinion on Twitter. In the end, Sweden scored 12,705 tweets during this half hour, and Russia scored 13,917.
Does this mean that Sweden has cheated and that Russia should have won? Probably not. The strange voting system of the Eurovision, which gives as many voting points to Luxemburg and to Germany can easily create an imbalance between the votes and the sheer representation of the voters. Still, it seems that the Russian "babuchkis" gave an overall stronger impression.
In conclusion Sweden probably did not cheat. It's just that I can't appreciate what's good music when I hear it!